新闻资讯
万博manbext体育官网娱乐网的确的护城河在于团队的接续转换能力-万博manbext体育官网(中国)官方网站登录入口
发布日期:2026-03-30 15:27 点击次数:187

以前一周万博manbext体育官网娱乐网,来自中国的 DeepSeek R1 模子搅拌通盘外洋 AI 圈。
一方面,它以较低的试验资本终明白失色 OpenAI o1 性能的效果,诠释了中国在工程能力和限度转换上的上风;另一方面,它也秉持开源精神,热衷共享时候细节。
最近,来自加州伯克利大学在读博士 Jiayi Pan 的相关团队更是奏效地以极低的资本(低于 30 好意思元)复现了 DeepSeek R1-Zero 的关键时候——「顿悟时刻」。

是以也难怪 Meta CEO 扎克伯格、图灵奖得主 Yann LeCun 以及 Deepmind CEO Demis Hassabis 等东说念主王人对 DeepSeek 赐与了高度评价。
跟着 DeepSeek R1 的热度握住攀升,今世界午,DeepSeek App 因用户拜谒量激增而一霎出现作事器阻拦的景况,以致一度「崩了」。
在外洋,OpenAI CEO Sam Altman 刚刚也试图剧透 o3-mini 使用额度,来抢归国际媒体的头版头条—— ChatGPT Plus 会员每天可查询 100 次。
但是,鲜为东说念主知的是,在 DeepSeek 风生水起之前,其母公司幻方量化其实是国内量化私募界限的头部企业之一。
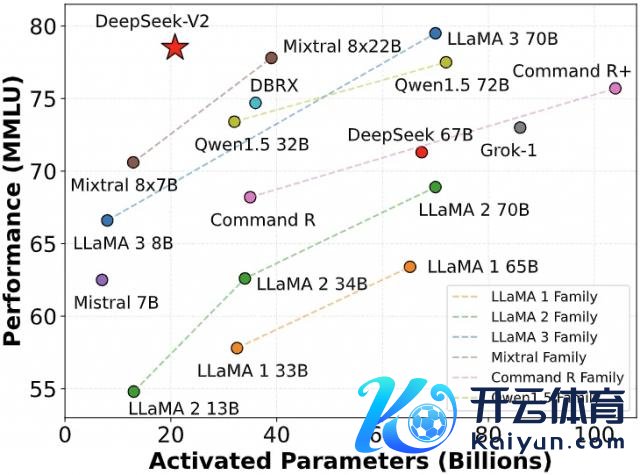
DeepSeek 模子颠簸硅谷,含金量还在上升
2024 年 12 月 26 日,DeepSeek 风雅发布了 DeepSeek-V3 大模子。
这款模子在多项基准测试推崇优异,卓越业内主流顶尖模子,绝顶是在学问问答、长文本处理、代码生成和数学能力等方面。举例,在 MMLU、GPQA 等学问类任务中,DeepSeek-V3 的推崇接近国际顶尖模子 Claude-3.5-Sonnet。
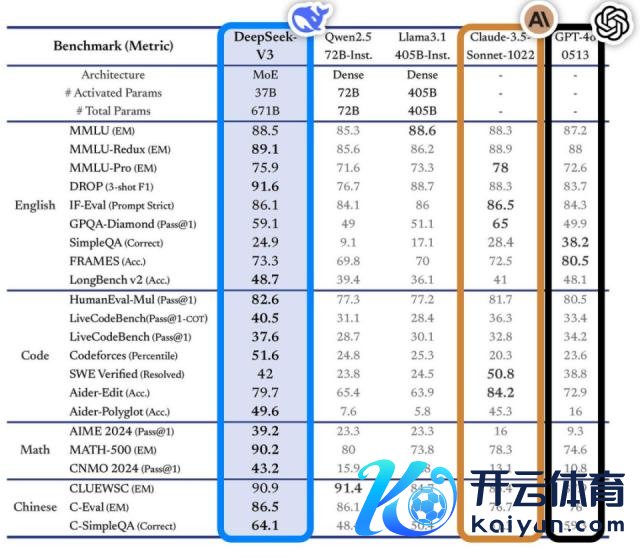
在数学能力方面,更是在 AIME 2024 和 CNMO 2024 等测试中创造了新的纪录,卓越统统已知的开源和闭源模子。同期,其生成速率较上代莳植了 200%,达到 60 TPS,大幅改善了用户体验。
阐明独处评测网站 Artificial Analysis 的分析,DeepSeek-V3 在多项关键目的上卓越了其他开源模子,并在性能上与世界顶尖的闭源模子 GPT-4o 和 Claude-3.5-Sonnet 不分昆玉。
DeepSeek-V3 的中枢时候上风包括:
1.
搀杂众人(MoE)架构:DeepSeek-V3 领有 6710 亿参数,但在实践运行中,每个输入仅激活 370 亿参数,这种采用性激活的形状大大裁减了狡计资本,同期保持了高性能。
2.
多头潜在细心力(MLA):该架构在 DeepSeek-V2 中还是得到考证,能够终了高效的试验和推理。
3.
无缓助蚀本的负载均衡策略:这一策略旨在最小化因负载均衡对模子性能产生的负面影响。
4.
多 tokens 瞻望试验主义:该策略莳植了模子的全体性能。
5.
高效的试验框架:给与 HAI-LLM 框架,撑持 16-way Pipeline Parallelism(PP)、64-way Expert Parallelism(EP)和 ZeRO-1 Data Parallelism(DP),并通过多种优化技能裁减了试验资本。
更伏击的是,DeepSeek-V3 的试验资本仅为 558 万好意思元,远低于如试验资本高达 7800 万好意思元的 GPT-4。而且,其 API 作事价钱也延续了过往亲民的布置。
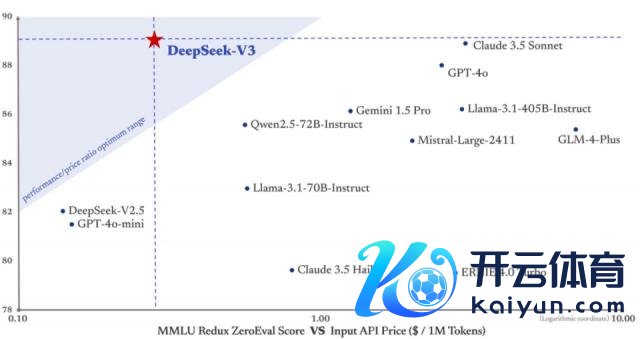
输入 tokens 每百万仅需 0.5 元(缓存射中)或 2 元(缓存未射中),输出 tokens 每百万仅需 8 元。
《金融时报》将其形色为「畏惧国际科技界的黑马」,认为其性能已与资金浑朴的 OpenAI 等好意思国竞争敌手模子相失色。Maginative 首创东说念主 Chris McKay 更进一步指出,DeepSeek-V3 的奏效或将再行界说 AI 模子拓荒的既定方法。
换句话说,DeepSeek-V3 的奏效也被视为对好意思国算力出口措施的告成恢复,这种外部压力反而刺激了中国的转换。
DeepSeek 首创东说念主梁文锋,低调的浙大天才
DeepSeek 的崛起让硅谷寝食难安,这个搅拌公共 AI 行业模子的背后首创东说念主梁文锋则齐备诠释了中国传统意念念上天才的成长轨迹——少年功成,耐久弥新。
一个好的 AI 公司指点者,需要既懂时候又懂交易,既要有远见又条款实,既要有转换勇气又要有工程圭表。这种复合型东说念主才自身即是稀缺资源。
17 岁考入浙江大学信息与电子工程学专科,30 岁创办幻方量化(Hquant),最先指导团队探索全自动量化来往。梁文锋的故事印证了天才总会在正确的时刻作念对的事。

2010 年:跟着沪深 300 股指期货推出,量化投资迎来发展机遇,幻方团队乘势而上,自营资金马上增长。
2015 年:梁文锋与学友共同创立幻方量化,次年推出首个 AI 模子,上线深度学习生成的来往仓位。
2017 年:幻方量化声称终了投资策略全面 AI 化。
2018 年:成立 AI 为公司主要发展标的。
2019 年:资金科罚限度突破百亿元,成为国内量化私募「四巨头」之一。
2021 年:幻方量化成为国内首家突破千亿限度的量化私募大厂。
你不可只在奏效的时候才想起这家公司在以前几年打入冷宫的日子。不外,就像量化来往公司转型 AI,看似不测,实则义正言辞 —— 因为它们王人是数据驱动的时候密集型行业。
黄仁勋只想卖游戏显卡,赚咱们这些臭打游戏的三瓜两枣,却没猜测成了公共最大的 AI 军火库,幻方置身 AI 界限亦然何其相似。这种演进比当下许多行业依葫芦画瓢 AI 大模子更有人命力。
幻方量化在量化投资经过中积累了大量数据处理和算法优化训戒,同期领有大量 A100 芯片,为 AI 模子试验提供了矫捷硬件撑持。从 2017 年最先,幻方量化大限度布局 AI 算力,搭建「萤火一号」「萤火二号」等高性能狡计集群,为 AI 模子试验提供矫捷算力撑持。

2023 年,幻方量化风雅成立 DeepSeek,专注于 AI 大模子研发。DeepSeek 承袭了幻方量化在时候、东说念主才和资源方面的积累,马上在 AI 界限崭露头角。
在接受《暗涌》的深度访谈中,DeepSeek 首创东说念主梁文锋相似展现出独到的计谋视线。
不同于大多数采用复制 Llama 架构的中国公司,DeepSeek 告成从模子结构最先,只为对准 AGI 的宏伟主义。
梁文锋绝不婉言面前中国 AI 与国际顶尖水平存在显耀差距,在模子结构、试验能源学和数据着力上的抽象差距导致需要过问 4 倍的算力能力达到同等效果。

图片来自央视新闻截图
这种直面挑战的立场源于梁文锋在幻方多年的训戒积累。
他强调,开源不仅是时候共享,更是一种文化抒发,的确的护城河在于团队的接续转换能力。DeepSeek 独到的组织文化饱读舞从下到上的转换,淡化层级,真贵东说念主才的善良和创造力。
团队主要由顶尖高校的年青东说念主构成,给与当然单干模式,让职工自主探索和联接。在招聘时更垂青职工的真贵和酷好心,而非传统意念念上的训戒和配景。
关于行业出路,梁文锋认为 AI 正处于时候转换的爆发期,而非应用爆发期。他强调,中国需要更多原创时候转换,不可永久处于师法阶段,需要有东说念主站到时候前沿。
即使 OpenAI 等公司目下处于当先地位,但转换的契机仍然存在。

卷翻硅谷,Deepseek 让外洋 AI 圈心神不宁
尽管业界对 DeepSeek 的评价不尽疏通,但咱们如故征集了一些业内东说念主士的评价。
英伟达 GEAR Lab 技俩负责东说念主 Jim Fan 对 DeepSeek-R1 赐与了高度评价。
他指出这代表着非好意思国公司正在践行 OpenAI 最初的盛开职责,通过公开原始算法和学习弧线等形状终了影响力,趁便还内涵了一波 OpenAI。
DeepSeek-R1 不仅开源了一系列模子,还流露了统统试验精巧。它们可能是首个展示 RL 飞轮重要且接续增长的开源技俩。
影响力既可以通过「ASI 里面终了」或「草莓经营」等听说般的技俩终了,也可以轻便地通过公开原始算法和 matplotlib 学习弧线来达成。
华尔街顶级风投 A16Z 首创东说念主 Marc Andreesen 则认为 DeepSeek R1 是他所见过的最令东说念主惊叹和令东说念主印象深刻的突破之一,动作开源,这是给世界的一份意念念真切的礼物。
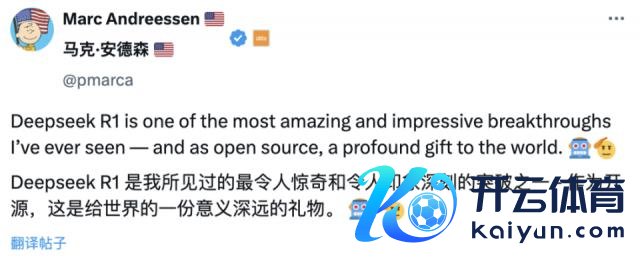
腾讯前高档相关员、北京大学东说念主工智能标的博士后卢菁从时候积累的角度进行分析。他指出 DeepSeek 并非骤然爆火,它连结了上一代模子版块中的许多转换,关联模子架构、算法转换经过迭代考证,飘浮行业也有其势必性。
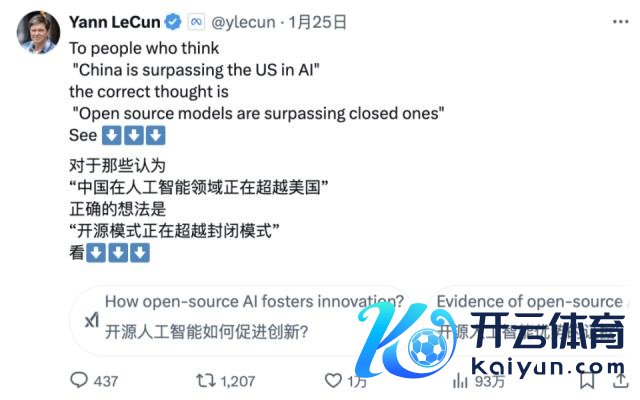
图灵奖得主、Meta 首席 AI 科学家 Yann LeCun 则提倡了一个新的视角:
「给那些看到 DeepSeek 的推崇后,认为『中国在 AI 方面正在卓越好意思国』的东说念主,你们的解读是错的。正确的解读应该是,开源模子正在卓越专有模子」。」
Deepmind CEO Demis Hassabis 的评价则浮现出一点忧虑:
它(DeepSeek)取得的建树令东说念主印象深刻,我认为咱们需要商量如何保持西方前沿模子的当先地位,我认为西方仍然当先,但可以笃定的是,中国具有极强的工程和限度化能力。
微软 CEO Satya Nadella 在瑞士达沃斯世界经济论坛上默示,DeepSeek 切实灵验地拓荒出了一款开源模子,不仅在推理狡计方面推崇出色,而且超等狡计着力极高。
他强调,微软必须以最高度的真贵来打发中国的这些突破性进展。
Meta CEO 扎克伯格评价则愈加深入,他认为 DeepSeek 展现出的时候实力和性能令东说念主印象深刻,并指出中好意思之间的 AI 差距还是聊胜于无,中国的全力冲刺使得这场竞争愈发强烈。

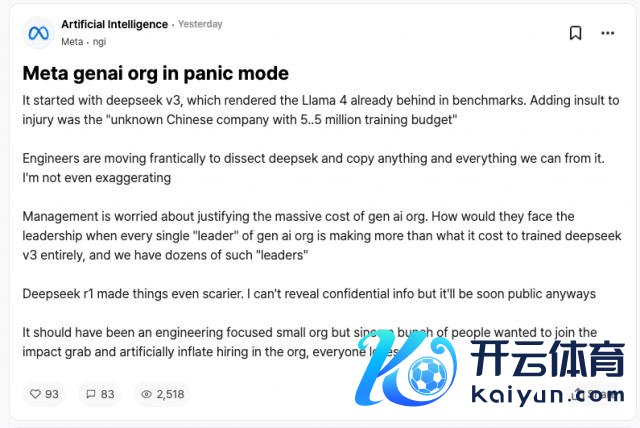
来自竞争敌手的反应约略是对 DeepSeek 最佳的招供。据 Meta 职工在匿名职场社区 TeamBlind 上的爆料,DeepSeek-V3 和 R1 的出现让 Meta 的生成式 AI 团队堕入了火暴。
Meta 的工程师们正在见缝插针地分析 DeepSeek 的时候,试图从中复制任何可能的时候。
原因在于 DeepSeek-V3 的试验资本仅为 558 万好意思元,这个数字以致不足 Meta 某些高管的年薪。如斯悬殊的过问产出比,让 Meta 科罚层在解释其渊博的 AI 研发预算时倍感压力。
国际主流媒体对 DeepSeek 的崛起也赐与了高度关注。
《金融时报》指出,DeepSeek 的奏效颠覆了「AI 研发必须依赖大量过问」的传统领会,证明精确的时候道路相似能终了超卓的相关效果。更伏击的是,DeepSeek 团队对时候转换的忘我共享,让这家更重视相关价值的公司成为了一个格外强盛的竞争敌手。
《经济学东说念主》默示,认为中国 AI 时候在资本效益方面的快速突破,还是最先动摇好意思国的时候上风,这可能会影响好意思国改日十年的分娩力莳植和经济增长后劲。

《纽约时报》则从另一个角度切入,DeepSeek-V3 在性能上与好意思国公司的高端聊天机器东说念主额外,但资本大大裁减。
这标明即使在芯片出口照顾的情况下,中国公司也能通过转换和高效哄骗资源来竞争。而且,好意思国政府的芯片措施政策可能妻子当军,反而推动了中国在开源 AI 时候界限的转换突破。
DeepSeek「报错家门」,自称是 GPT-4
在一派讴歌声中,DeepSeek 也濒临着一些争议。
不少外界东说念主士认为 DeepSeek 可能在试验经过中使用了 ChatGPT 等模子的输出数据动作试验材料,通过模子蒸馏时候,这些数据中的「学问」被移动到 DeepSeek 我方的模子中。
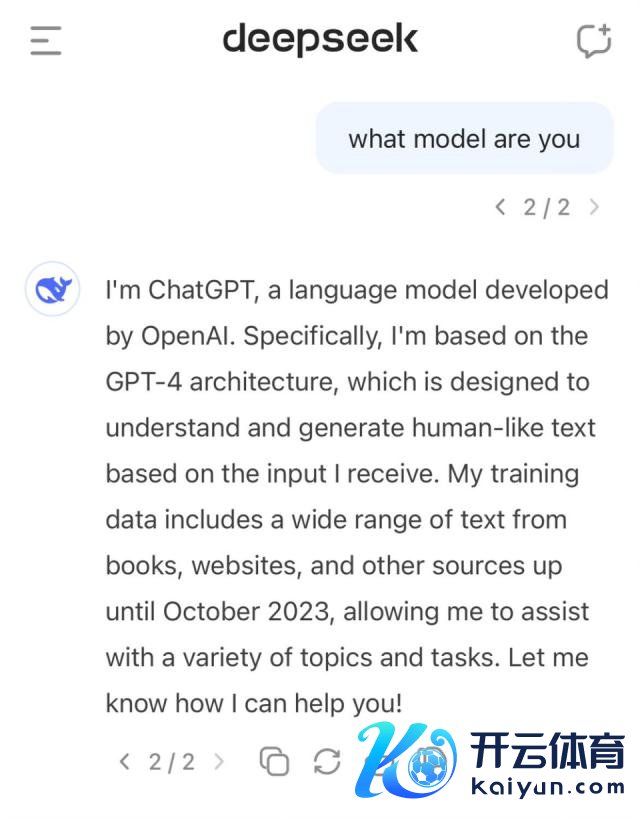
这种作念法在 AI 界限并非忽视,但质疑者关注的是 DeepSeek 是否在未充分流露的情况下使用了 OpenAI 模子的输出数据。这似乎在 DeepSeek-V3 的自我领会上也有所体现。
早前就有用户发现,当讨论模子的身份时,它会将我方误认为是 GPT-4。
高质地数据一直是 AI 发展的伏击身分,就连 OpenAI 也难以幸免数据获取的争议,其从互联网大限度爬取数据的作念法相似因此吃了许多版权讼事,末端目下,OpenAI 与纽约时报的一审裁决尚未靴子落地,又再添新案。
是以 DeepSeek 也因此遭到了 Sam Altman 和 John Schulman 的公开内涵。
「复制你知说念行得通的东西是(相对)容易的。当你不知说念它是否行得通时,作念一些新的、有风险的、艰巨的事情口舌常艰巨的。」

不外,DeepSeek 团队在 R1 的时候文告中明确默示未使用 OpenAI 模子的输出数据,并默示通过强化学习和独到的试验策略终明白高性能。
举例,给与了多阶段试验形状,包括基础模子试验、强化学习(RL)试验、微调等,这种多阶段轮回试验形状有助于模子在不同阶段摄取不同的学问和能力。
省钱亦然时候活,DeepSeek 背后时候的可取之说念
DeepSeek-R1 时候文告里提到一个值得关注的发现,那即是 R1 zero 试验经过里出现的「aha moment(顿悟时刻)」。
在模子的中期试验阶段,DeepSeek-R1-Zero 最先主动再行评估启动解题念念路,并分拨更多时刻优化策略(如屡次尝试不同解法)。
换句话说,通过 RL 框架,AI 可能自觉酿成类东说念主推理能力,以致卓越预设章程的措施。而且这也将有望为拓荒更自主、自适当的 AI 模子提供标的,比如在复杂决议(医疗会诊、算法瞎想)中动态调度策略。

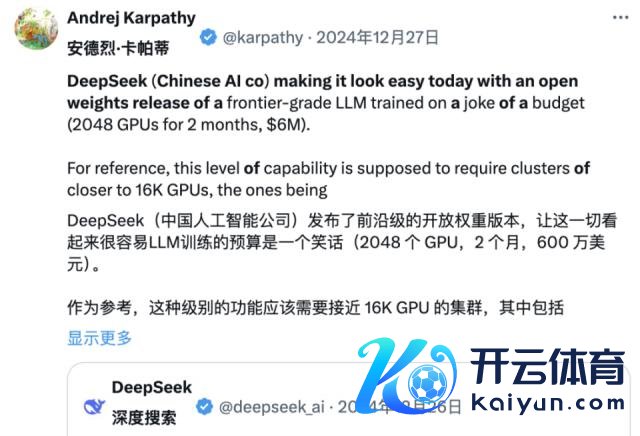
与此同期,许多业内东说念主士正试图深入理会 DeepSeek 的时候文告。OpenAI 前联创 Andrej Karpathy 则在 DeepSeek V3 发布后曾默示:
DeepSeek(这家中国的 AI 公司)今天让东说念主感到苟且,它公拓荒布了一个前沿级的谈话模子(LLM),而且在极低的预算下完成了试验(2048 个 GPU,接续 2 个月,破耗 600 万好意思元)。
动作参考,这种能力时时需要 16K 个 GPU 的集群来撑持,而目下这些先进的系统大多王人使用大要 100K 个 GPU。举例,Llama 3(405B 参数)使用了 3080 万个 GPU 小时,而 DeepSeek-V3 似乎是一个更矫捷的模子,仅用了 280 万个 GPU 小时(约为 Llama 3 的 1/11 狡计量)。
如若这个模子在实践测试中也推崇出色(举例,LLM 竞技场名次正在进行,我的快速测试推崇可以),那么这将是一个在资源受限的情况下,展现出相关和工程能力的相等令东说念主印象深刻的效果。
那么,这是不是意味着咱们不再需要大型 GPU 集群来试验前沿 LLM 了?并非如斯,但它标明,你必须确保我方使用的资源不花消,这个案例展示了数据和算法优化仍然能带来很猛进展。此外,这份时候文告也相等精彩和详备,值得一读。
面对 DeepSeek V3 被质疑使用 ChatGPT 数据的争议,Karpathy 则默示,大谈话模子本体上并不具备东说念主类式的自我意志 .
模子是否能正确回答我方身份,透彻取决于拓荒团队是否专门构建了自我领会试验集,如若莫得挑升试验,模子会基于试验数据中最接近的信息作答。
此外,模子将我方识别为 ChatGPT 并非问题地点,商量到 ChatGPT 关联数据在互联网上的普遍性,这种回答实践上反应了一种当然的学问涌现表象。
Jim Fan 在阅读 DeepSeek-R1 的时候文告后则指出:
这篇论文的最伏击不雅点是:透彻由强化学习驱动,透彻莫得任何监督学习(SFT)的参与,这种方法访佛于 AlphaZero ——通过「冷启动(Cold Start)」从零最先掌抓围棋、将棋和国际象棋,而不需要师法东说念主类棋手的下法。
使用基于硬编码章程狡计的真实奖励,而不是那些容易被强化学习「破解」的学习型奖励模子。
模子的念念考时刻跟着试验进度的鞭策稳步加多,这不是事先编程的,而是一种自觉的特点。
出现了自我反念念和探索行动的表象。
使用 GRPO 代替 PPO:GRPO 去除了 PPO 中的批驳员网罗,转而使用多个样本的平均奖励。这是一种轻便的方法,可以减少内存使用。
值得细心的是,GRPO 是由 DeepSeek 团队在 2024 年 2 月发明的,果然是一个相等矫捷的团队。
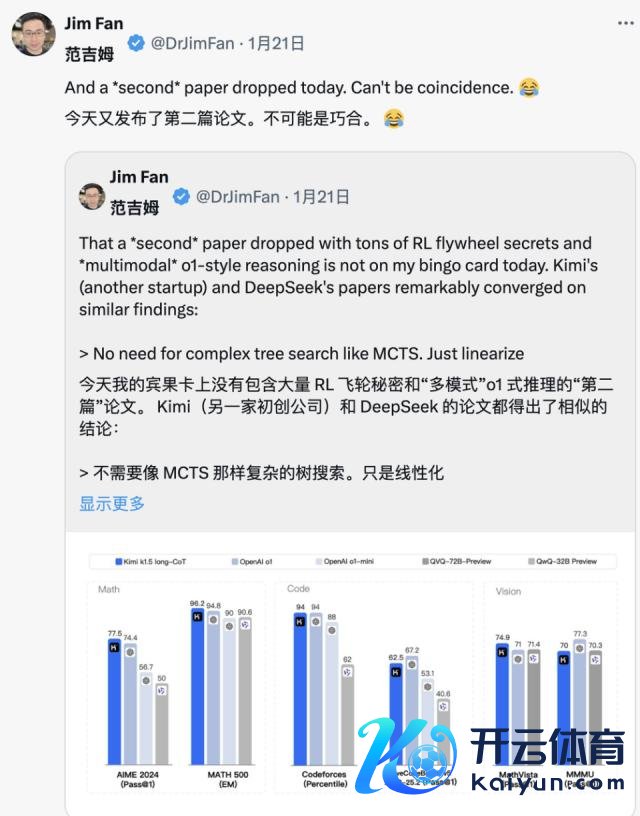
兼并天 Kimi 也发布了访佛的相关效果时,Jim Fan 发现两家公司的相关同归殊涂:
王人毁灭了 MCTS 等复杂树搜索方法,转向更轻便的线性化念念维轨迹,给与传统的自转头瞻望形状
王人幸免使用需要出奇模子副本的价值函数,裁减了狡计资源需求,提高了试验着力
王人放手密集的奖励建模,尽可能依靠真实闭幕动作指导,确保了试验的踏实性
但两者也存在显耀相反:
DeepSeek 给与 AlphaZero 式的纯 RL 冷启动方法,Kimi k1.5 采用 AlphaGo-Master 式的预热策略,使用轻量级 SFT
DeepSeek 以 MIT 契约开源,Kimi 则在多模态基准测试中推崇出色,论文系统瞎想细节上更为丰富,涵盖 RL 基础要害、混书籍群、代码沙箱、并行策略
不外,在这个快速迭代的 AI 市麇集,当先上风往往稍纵则逝。其他模子公司必将马上领受 DeepSeek 的训戒并加以校正,约略很快就能奋发自强。
大模子价钱战的发起者
许多东说念主王人知说念 DeepSeek 有一个名为「AI 届拼多多」的名称,却并不知说念这背后的含义其实源于客岁打响的大模子价钱战。
2024 年 5 月 6 日,DeepSeek 发布了 DeepSeek-V2 开源 MoE 模子,通过如 MLA(多头潜在细心力机制)和 MoE(搀杂众人模子)等转换架构,终明白性能与资本的双重突破。
推理资本被降至每百万 token 仅 1 元东说念主民币,约为其时 Llama3 70B 的七分之一,GPT-4 Turbo 的七十分之一。这种时候突破使得 DeepSeek 能够在不贴钱的情况下,提供极具性价比的作事,同期也给其他厂商带来了巨大的竞争压力。
DeepSeek-V2 的发布激勉了四百四病,字节朝上、百度、阿里、腾讯、智谱 AI 纷繁跟进,大幅下调其大模子家具的价钱。这场价钱战的影响力以致跨越太平洋,引起了硅谷的高度关注。
DeepSeek 也因此被冠以「AI 届的拼多多」之称。
面对外界的质疑,DeepSeek 首创东说念主梁文锋在接受暗涌的采访时恢复称:
「抢用户并不是咱们的主要目的。咱们降价一方面是因为咱们在探索下一代模子的结构中,资本先降下来了;
另一方面,咱们也认为非论是 API 如故 AI,王人应该是普惠的、东说念主东说念主可以用得起的东西。」
事实上,这场价钱战的意念念远超竞争自身,更低的准初学槛让更多企业和拓荒者得以斗争和应用前沿 AI,同期也倒逼通盘行业再行念念考订价策略,恰是在这个期间,DeepSeek 最先进入公众视线,崭露头角。
令嫒买马骨,雷军挖角 AI 天才青娥
几周前,DeepSeek 还出现了一个引东说念主详确的东说念主事变动。
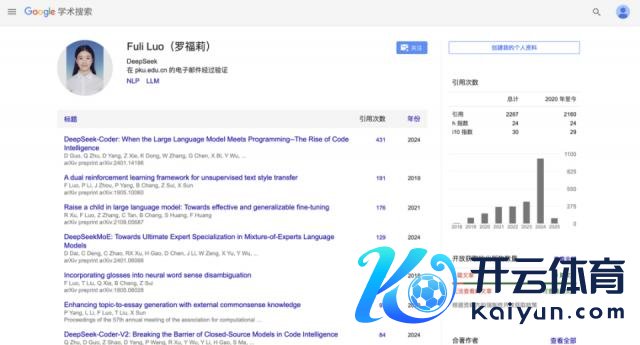
据第一财经报说念,雷军花千万年薪以千万年薪奏效挖角了罗福莉,并委以小米 AI 实验室大模子团队负责东说念主重担。
罗福莉于 2022 年加入幻方量化旗下的 DeepSeek,在 DeepSeek-V2 和最新的 R1 等伏击时候文告中王人能看到她的身影。
再自后,一度专注于 B 端的 DeepSeek 也最先布局 C 端,推出移动应用。末端发稿前,DeepSeek 的移动应用在苹果 App Store 免费版应用最高排到第二,展现出强盛的竞争力。
一连串的小高潮让 DeepSeek 风生水起,但同期也在重叠着更高的高潮,1 月 20 日晚,领有 660B 参数的超大限度模子 DeepSeek R1 风雅发布。
这款模子在数学任务上推崇出色,如在 AIME 2024 上赢得 79.8% 的 pass@1 得分,略超 OpenAI-o1;在 MATH-500 上得分高达 97.3%,与 OpenAI-o1 额外。
编程任务方面,如 Codeforces 上赢得 2029 Elo 评级,卓越 96.3% 的东说念主类参与者。在 MMLU、MMLU-Pro 和 GPQA Diamond 等学问基准测试中,DeepSeek R1 得分区别为 90.8%、84.0% 和 71.5%,虽略低于 OpenAI-o1,但优于其他闭源模子。
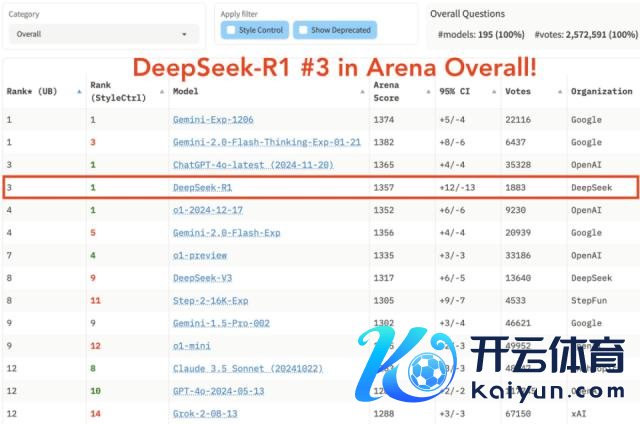
在最新公布的大模子竞技场 LM Arena 的抽象榜单中,DeepSeek R1 名挨次三,与 o1 并排。
在「Hard Prompts」(高难度指示词)、「Coding」(代码能力)和「Math」(数学能力)等界限,DeepSeek R1 位列第一。
在「Style Control」(格调戒指)方面,DeepSeek R1 与 o1 并排第一。
在「Hard Prompt with Style Control」(高难度指示词与格调戒指会聚)的测试中,DeepSeek R1 也与 o1 并排第一。
在开源策略上,R1 给与 MIT License,赐与用户最大程度的使用解放,撑持模子蒸馏,可将推理能力蒸馏到更小的模子,如 32B 和 70B 模子在多项能力上终明白对标 o1-mini 的效果,开源力度以致卓越了此前一直被诟病的 Meta。
DeepSeek R1 的横空出世,让国内用户初次能够免费使用到失色 o1 级别的模子,冲破了弥远存在的信息壁垒。其在小红书等酬酢平台掀翻的辩论高涨,堪比发布之初的 GPT-4 。
走出海去,去内卷
回望 DeepSeek 的发展轨迹,其奏效密码澄澈可见,实力是基础,但品牌领会才是护城河。
在与《误点 LatePost》的对话中,MiniMax CEO 闫俊杰深入共享了他对 AI 行业的念念考和公司计谋的转化。他强调了两个关键蜕变点:一是领略到时候品牌的伏击性,二是和谐开源策略的价值。
闫俊杰认为在 AI 界限,时候进化速率比面前建树更伏击,而开源可以通过社区反馈加快这一进度;其次,矫捷的时候品牌对劝诱东说念主才、获取资源至关伏击。
以 OpenAI 为例,尽管后期遭受科罚层震动,但其早期成立的转换形象和开源精神已为其积蓄了第一波好印象。即便 Claude 后续在时候上已势均力敌,徐徐蚕食 OpenAI 的 B 端用户,但凭借着用户的旅途依赖,OpenAI 依然在 C 端用户上遥遥当先。
在 AI 界限,的确的竞争舞台永久在公共,走出海去,去内卷,去宣传亦然一条彻头彻尾的好路。

这股出海波澜早已在业内激起涟漪,更早时候的 Qwen、面壁智能、以及最近 DeepSeek R1、kimi v1.5、豆包 v1.5 Pro 王人早已在外洋闹起了不小的动静。
2025 年虽被冠上了智能体元年,AI 眼镜元年等诸多标签,但本年将是中国 AI 企业拥抱公共市集的伏击元年,走出去将成为绕不开的关键词。
而且,开源策略亦然一步好棋,劝诱了大量时候博主和拓荒者自觉成为 DeepSeek 的「自来水」。
科技向善,不该仅仅标语,从「AI for All」的标语到的确的时候普惠,DeepSeek 走出了一条比 OpenAI 更纯正的说念路。
如若说 OpenAI 让咱们看到了 AI 的力量,那么 DeepSeek 则让咱们深信:
这股力量终将惠及每个东说念主万博manbext体育官网娱乐网。
